
今天,我们发布了Qwen2.5-Omni,Qwen 模型家族中新一代端到端多模态旗舰模型。该模型专为全方位多模态感知设计,能够无缝处理文本、图像、音频和视频等多种输入形式,并通过实时流式响应同时生成文本与自然语音合成输出。
该模型现已在 Hugging Face、ModelScope、DashScope 和 GitHub上开源开放,你可以通过我们的Demo体验互动功能,或是通过Qwen Chat 直接发起语音或视频聊天,沉浸式体验全新的 Qwen2.5-Omni 模型强大性能。
主要特点
Qwen2.5-Omni-7B demo
模型架构
Qwen2.5-Omni采用Thinker-Talker双核架构。Thinker 模块如同大脑,负责处理文本、音频、视频等多模态输入,生成高层语义表征及对应文本内容;Talker 模块则类似发声器官,以流式方式接收 Thinker实时输出的语义表征与文本,流畅合成离散语音单元。Thinker 基于 Transformer 解码器架构,融合音频/图像编码器进行特征提取;Talker则采用双轨自回归 Transformer 解码器设计,在训练和推理过程中直接接收来自 Thinker 的高维表征,并共享全部历史上下文信息,形成端到端的统一模型架构。
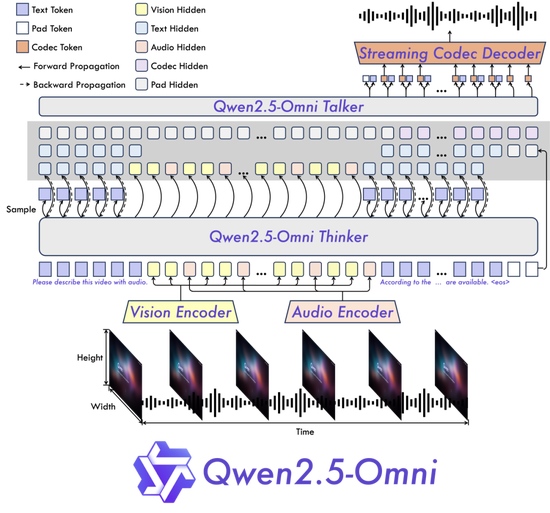
模型架构图
模型性能
Qwen2.5-Omni在包括图像,音频,音视频等各种模态下的表现都优于类似大小的单模态模型以及封闭源模型,例如Qwen2.5-VL-7B、Qwen2-Audio和Gemini-1.5-pro。
在多模态任务OmniBench,Qwen2.5-Omni达到了SOTA的表现。此外,在单模态任务中,Qwen2.5-Omni在多个领域中表现优异,包括语音识别(Common Voice)、翻译(CoVoST2)、音频理解(MMAU)、图像推理(MMMU、MMStar)、视频理解(MVBench)以及语音生成(Seed-tts-eval和主观自然听感)。
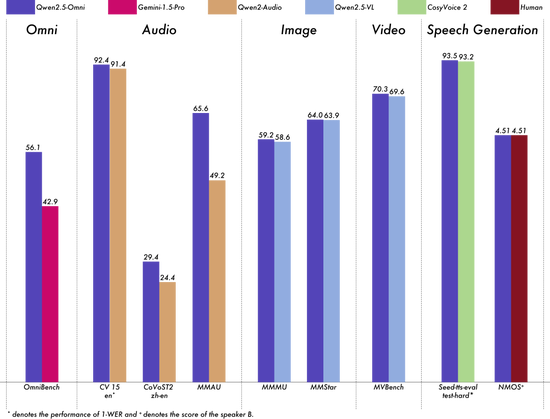
模型性能图
下一步
我们期待听到您的反馈,并看到您使用 Qwen2.5-Omni 开发的创新应用。在不久的将来,我们将着力增强模型对语音指令的遵循能力,并提升音视频协同理解能力。更值得期待的是,我们将持续拓展多模态能力边界,以发展成为一个全面的通用模型!
体验方式